















Tongcheng Travel is a market leader in China's online travel industry. It’s a one-stop shop for users' travel needs. As a technology-driven company, by using big data and AI capabilities, Tongcheng Travel can better understand the preferences and behaviors of users and provide them with customized products and services.
As our business grew rapidly, our unstructured data exceeded 1 billion files. In 2022, we built our object storage service. At that time, we were using CephFS as our distributed file system. However, as data volume continued to grow, the high complexity and operational challenges of CephFS became a bottleneck. Considering factors such as observability, stability, and management efficiency, we switched to JuiceFS, an open-source cloud-native distributed file system.
Currently, we’ve established an enterprise-grade storage platform on JuiceFS, including 20+ file systems and 2,000+ client mount points. The platform efficiently manages hundreds of millions of files and hundreds of terabytes of data. The daily operations require only one personnel. The platform is applied in multiple scenarios, including AI applications, container cloud environments, and application-level shared storage.
In this article, we’ll deep dive into why we replaced CephFS with JuiceFS, how we built a storage platform with JuiceFS, and our plans for the future.
File system selection: CephFS vs. JuiceFS
Before adopting JuiceFS, we used Ceph to provide object storage and distributed file system services. Later we migrated from CephFS to JuiceFS.
CephFS’ disadvantages
We found Ceph had these drawbacks:
- Its complex technical stack posed challenges for operation and maintenance, requiring significant expertise and experience.
- It has certain shortcomings in terms of maintainability and ecosystem development. This poses substantial challenges to ensuring daily stability.
JuiceFS’ advantages
JuiceFS offers several advantages:
- Its metadata and data separation design aligned well with our existing object storage and distributed database systems. This enables the team to leverage its technical expertise for troubleshooting and performance analysis.
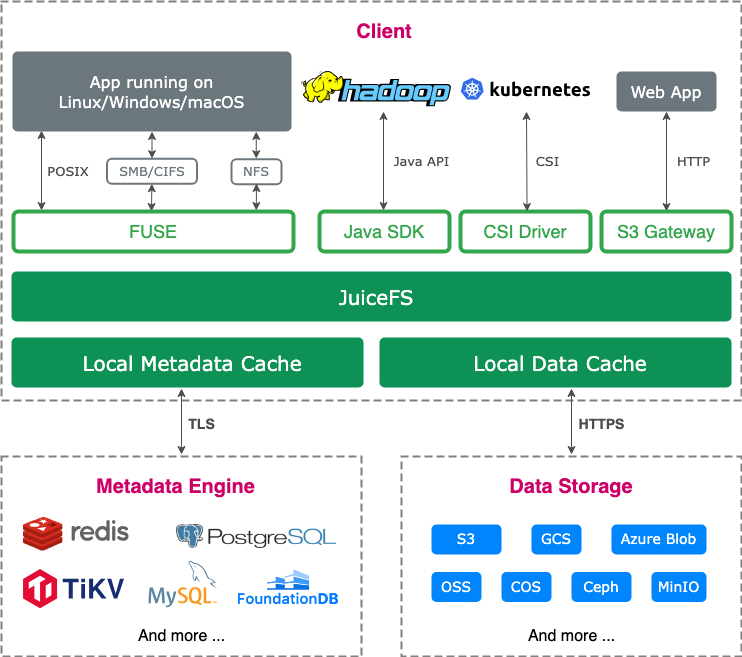
- It has a mature toolset, good POSIX compatibility, and strong cloud-native support. JuiceFS Container Storage Interface (CSI) provides flexible mounting options.
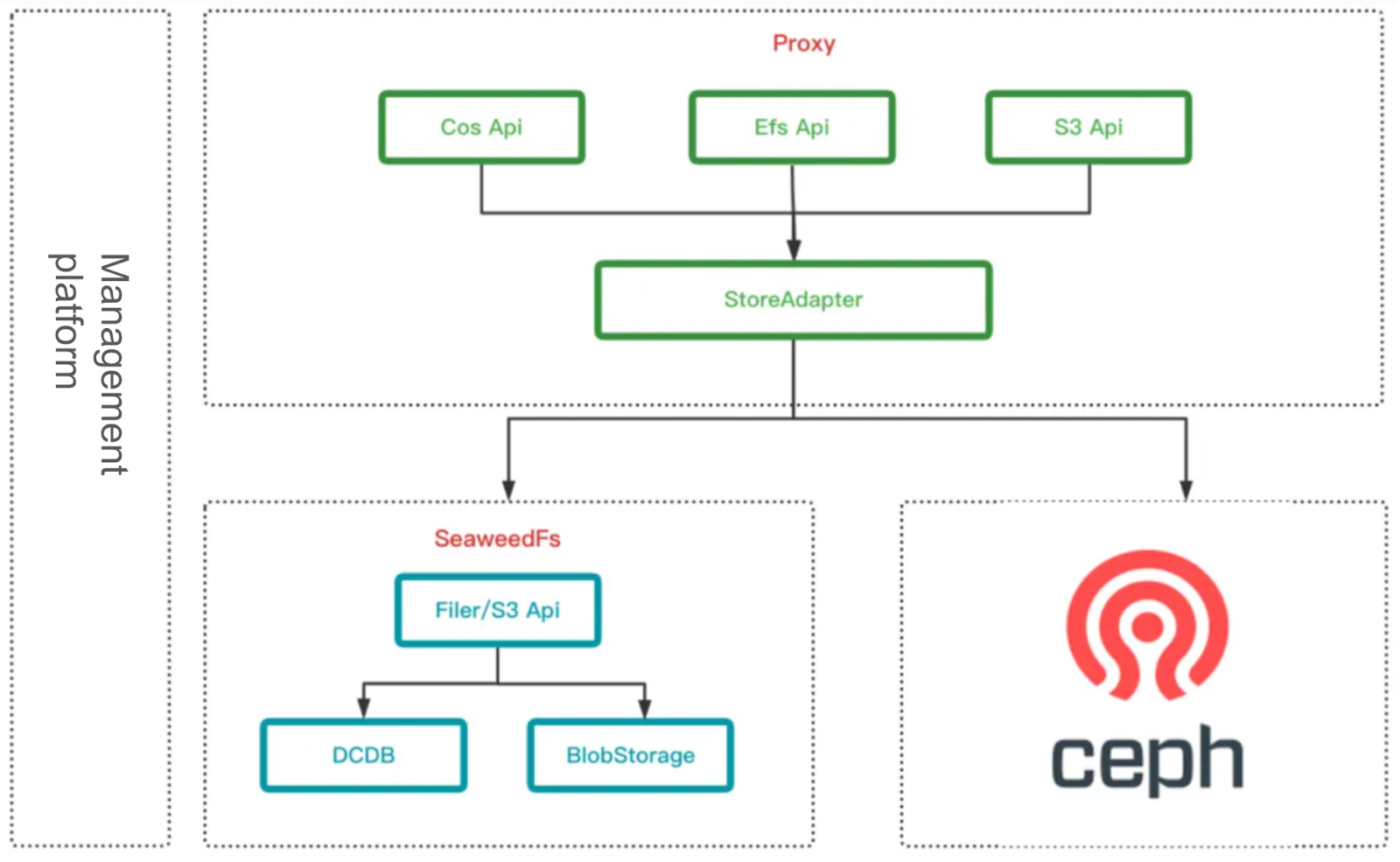
- It’s seamlessly integrated with our existing technology stack. We built an S3 cluster based on SeaweedFS, along with an S3 proxy compatible with SeaweedFS and Ceph. The S3 cluster utilized a master-replica mechanism to enable failover at the proxy layer. For metadata management, we used an internal distributed database (DCDB), with MySQL-compatible syntax.
Building a platform with JuiceFS
During the platform development process, observability, application integration, deployment, and data safety were key focus areas. We meticulously designed and optimized the system to ensure comprehensive monitoring and efficient service management.
Observability: We developed monitoring dashboards to track critical metrics comprehensively. The platform integrated with the company’s internal alerting system, setting rules for key metrics like capacity and interface latency. We also developed an auto-discovery tool to automatically identify active clients from the metadata engine and update the internal monitoring system in real time.
Application integration and deployment: We provided user-friendly tools to streamline application integration and deployment. These tools reduced operational complexity.
Data safety: We implemented comprehensive backups for critical file systems to ensure data integrity and availability.
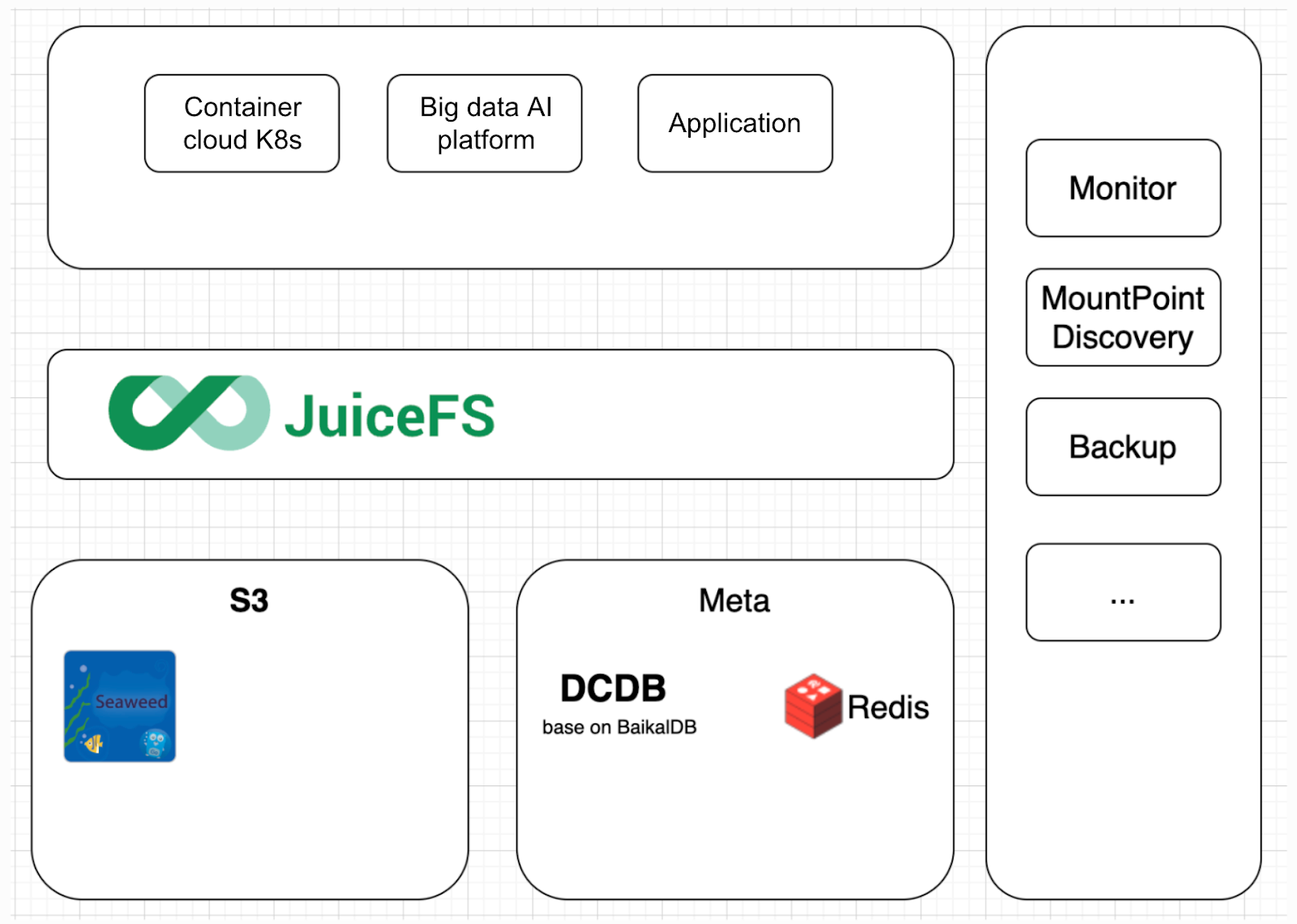
In terms of monitoring the specific content of alarms, we mainly focus on the server side. Key metrics include the average delay of metadata and S3 services, request success rate, and abnormal conditions. These metrics are critical for evaluating system performance and stability.
High-availability JuiceFS clusters: Single-IDC deployment
A typical scenario it addresses is the Kubernetes single-IDC cluster. Kubernetes itself is not a multi-IDC cluster; instead, each data center deploys an independent cluster, forming a single-IDC architecture. In this setup, various Kubernetes resources and services are typically confined to the same data center to avoid the latency, bandwidth consumption, and network complexity introduced by cross-IDC communication. In Kubernetes, JuiceFS primarily solves the need for persistent storage, rather than data sharing.
Moreover, for applications with higher performance requirements, traffic needs to remain within the same data center to avoid latency and bandwidth costs associated with cross-IDC transmission. Therefore, in these scenarios, a single-IDC solution is adopted, where JuiceFS-related services are deployed as independent clusters in each data center. This ensures that data storage and compute tasks are performed within the same data center, maximizing performance and reducing latency.
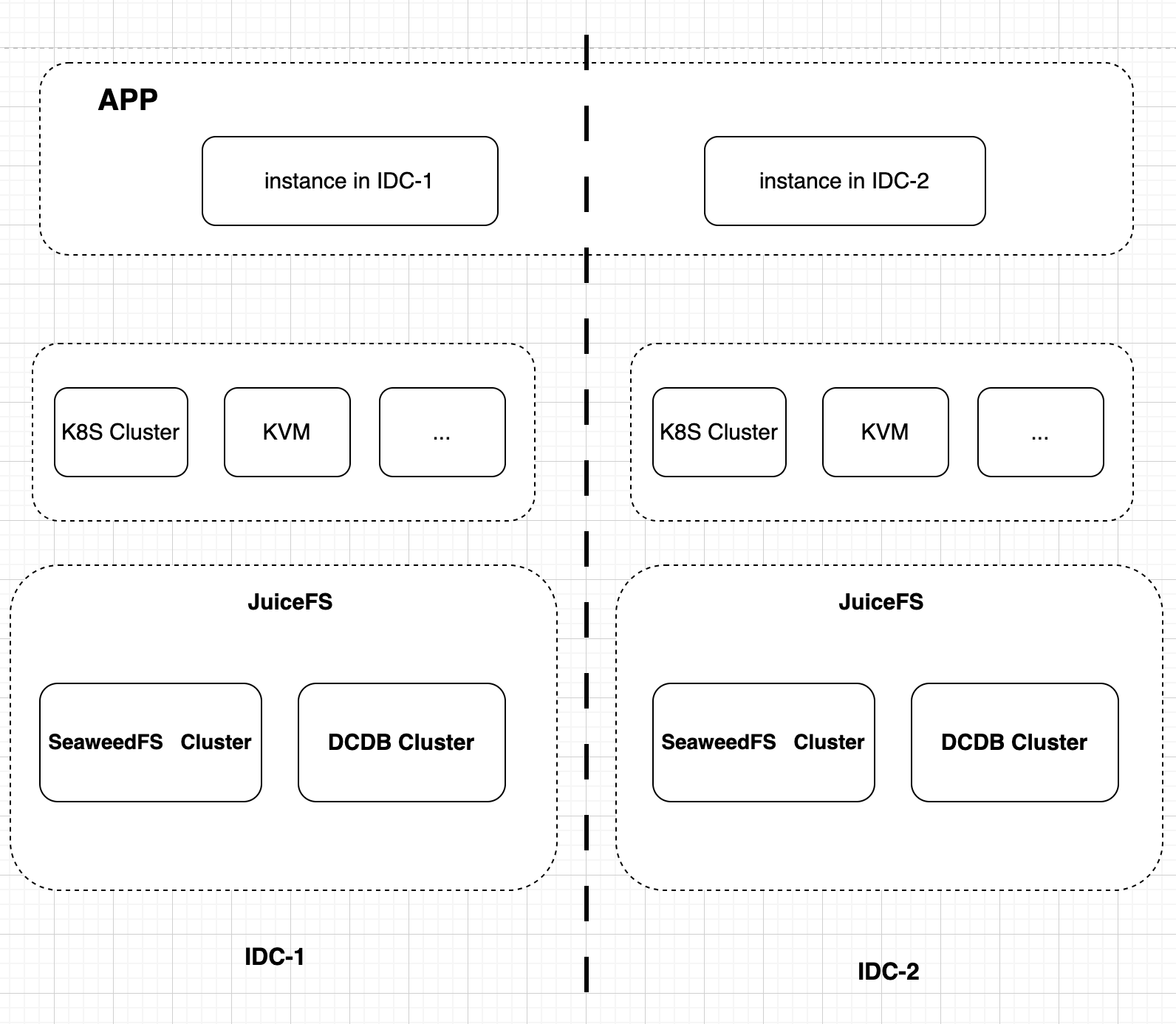
This approach is suitable for internal Kubernetes clusters and similar scenarios, primarily addressing the persistent storage requirements of stateful applications. By keeping traffic within the same IDC, it avoids performance bottlenecks caused by cross-IDC transmission. This ensures system stability and performance.
High-availability JuiceFS cluster: Cross-IDC closed loop
This deployment model is mainly designed for applications that are deployed across multiple data centers and require shared data. These applications need access to the same file system and also have high availability requirements. If the service in a data center fails, it’s not feasible to require all applications to switch to another data center. Thus, we adopt a cross-IDC deployment model for the backend service cluster.
In this model, object storage systems, such as the S3 cluster and DCDB, are deployed across data centers. Specifically, the S3 master node is deployed in each IDC to ensure global service accessibility. In addition, data replicas are stored in multiple data centers to improve data reliability and fault tolerance. DCDB also follows a cross-IDC deployment strategy, with its services deployed in each data center, and data replicas synchronized across data centers via its built-in replication mechanism.
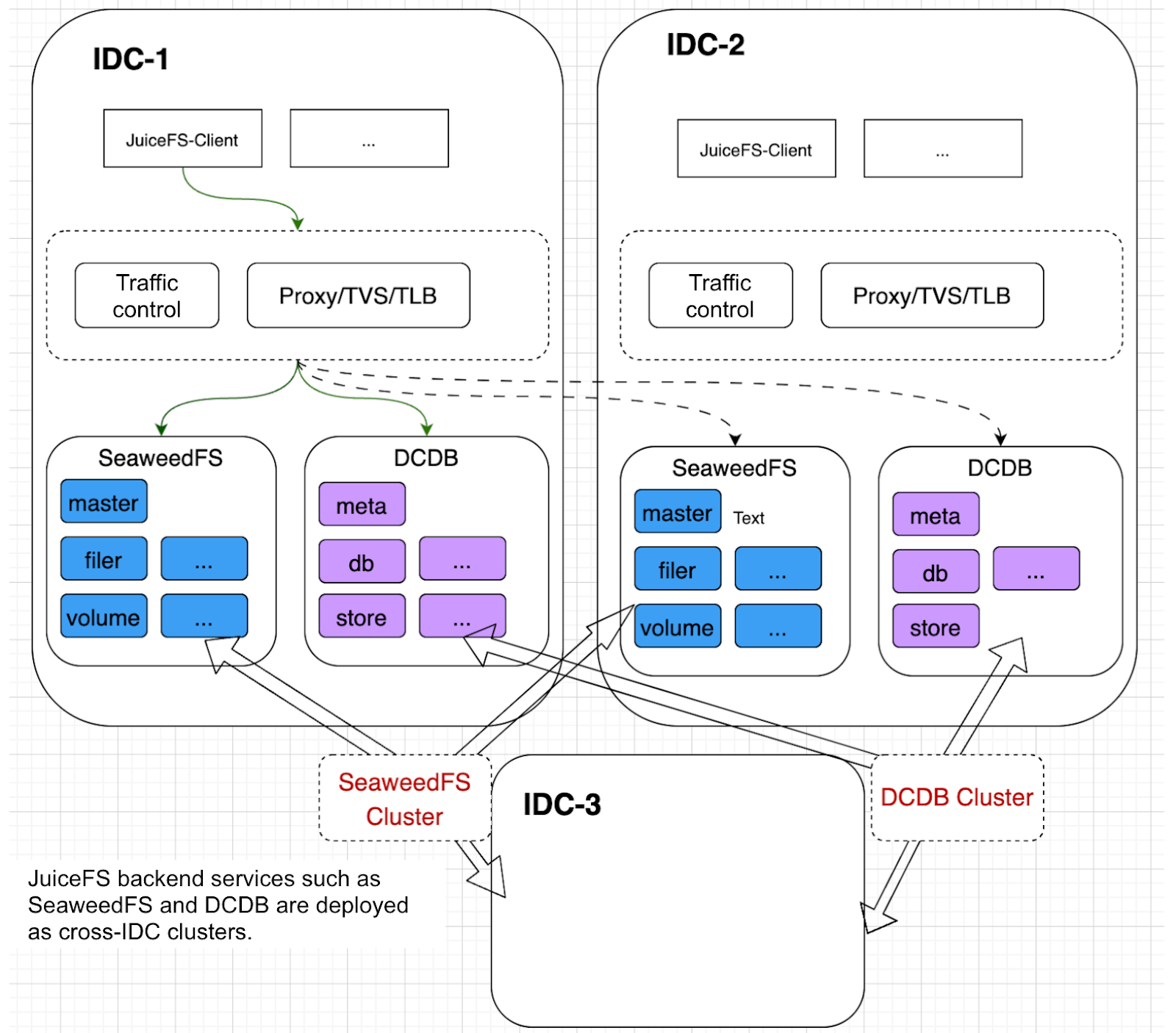
To optimize traffic paths and reduce latency and cost caused by cross-IDC transmission, we limit client requests to the local data center under normal circumstances. Traffic is forwarded through load balancing to the local S3 service node. This not only ensures performance but also reduces unnecessary cross-IDC traffic. However, due to the data synchronization and replication requirements within the cross-IDC cluster, there will still be cross-IDC traffic within the cluster.
In the case of a failure, such as an issue with the S3 service in one data center, we can switch the traffic entry to another center. This failover mechanism further ensures the high availability of the cluster.
JuiceFS benefits
JuiceFS’ architecture is highly compatible with our existing object storage and distributed database systems, making the integration process smooth. The entire project involved only two people. It was completed in six months, transitioning from CephFS to JuiceFS. Based on JuiceFS, we successfully built an enterprise-grade storage platform, significantly improving the observability, stability, and management efficiency of the storage system.
Main benefits of switching from CephFS to JuiceFS:
- Scalability and flexibility
- Seamless storage capacity scaling and easy handling of rapid data growth without downtime or disruption to existing services.
- Better adaptation to cloud computing and containerized environments, facilitating operations in multi-cloud or hybrid cloud environments.
- Simplified operations
- Comprehensive observability features, easily integrated into internal enterprise systems.
- Simplified operations, enhancing stability assurance.
- Data safety and reliability
- Stronger data fault tolerance, automatic failure recovery, and guaranteed high data availability.
- Robust backup and disaster recovery capabilities to ensure data’s long-term security and reliability.
Currently, JuiceFS provides strong storage solutions in multiple scenarios. It meets the needs of various applications:
- Container cloud platform: As the underlying infrastructure, JuiceFS effectively supports persistent storage for cloud centers, especially enabling data persistence for stateful applications via the CSI. It addressed the core needs for persistent storage in containerized environments.
- Big data and AI platform: In big data and AI applications, JuiceFS provides efficient support for massive data storage. Particularly during model training and data processing, it has significantly improved storage performance and meets the requirements of large-scale data storage.
- Application shared file scenarios: JuiceFS enables multiple application instances to easily share file resources. This replaces traditional data transfer methods and optimizes data exchange and resource sharing between applications.
- Data cold backup: Although object storage is widely adopted, some users still prefer file system interfaces. JuiceFS offers reliable data backup solutions for these scenarios, ensuring long-term data reliability and accessibility.
Future plans
About the distributed metadata engine
We’ve noticed that some scenarios require higher metadata performance. For these cases, we may consider using Redis. However, Redis currently faces capacity bottlenecks, because it uses only one node for data storage within the cluster, limiting its horizontal scalability.
Redis also has operational challenges. As a result, our team is developing a distributed key-value storage system.
About the distributed cache
We plan to introduce distributed caching to more effectively handle data storage and access needs in big data scenarios. This will further improve the performance and stability of the system.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.



